LLM Reference
LLMReference tracks 1,744 models and 133 providers so you ship with the fastest, cheapest, and best model for every task.
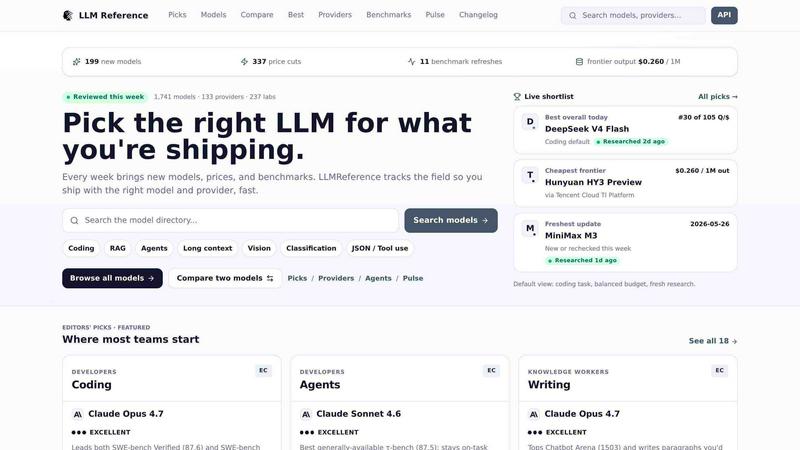
About LLM Reference
LLM Reference is a decision-support directory built for engineers and technology leaders who need to navigate the rapidly shifting landscape of large language models. The site tracks over 1,744 models from 133 providers and 235 research labs, refreshing its data weekly with new releases, verified price changes, and benchmark updates. This is not a static list; it is a live intelligence feed designed to answer one question: which model should you ship with today? The platform enables side-by-side comparison of any two models, offers editors picks for specific tasks like coding, agents, writing, research, image, video, and more, and features a Pulse feed that surfaces exactly what changed in the last week, including new models, price cuts, benchmark refreshes, and frontier pricing per million output tokens. The site is built for fast triage. You pick the right model for the job, see who serves it cheapest, and ship. Whether you are evaluating DeepSeek V4 Flash against Claude Sonnet 4.6 or checking the latest frontier output pricing from Tencent Cloud, LLM Reference gives you the battle-tested data to make a confident call. It is a competitive intelligence platform that turns model chaos into a clear, actionable shortlist.
Features of LLM Reference
Side-by-Side Model Comparison
Compare any two models head-to-head across performance benchmarks, pricing, context windows, and provider availability. This feature eliminates guesswork by putting raw data side by side, letting you see exactly how models stack up for your specific use case, whether that is coding, RAG, or long context tasks.
Editors Picks and Themed Boards
Curated selections for developers, knowledge workers, and creatives. Each board highlights the best model for a specific task, such as coding (Claude Opus 4.7 leads SWE-bench), agents (Claude Sonnet 4.6 tops tau-bench), or image generation (FLUX.2 Dev leads photoreal quality). These picks are refreshed with new research and benchmark results.
Pulse Feed for Weekly Market Changes
A live feed that tracks every change in the model market each week. Pulse reports new model releases, verified price cuts from providers, and benchmark refreshes across major suites. It also surfaces the current frontier output pricing, giving you a real-time view of who is undercutting whom.
Comprehensive Search and Filtering
Search the entire directory of 1,744 models by name, provider, or task. Filters allow you to narrow down by coding performance, RAG suitability, agent capability, vision, classification, JSON or tool use, and long context handling. This feature turns a massive dataset into a precise, actionable shortlist.
Use Cases of LLM Reference
Choosing a Model for a Coding Task
An engineering team shipping a new feature needs the best model for code generation and debugging. They use LLM Reference to compare Claude Opus 4.7, which leads SWE-bench Verified at 87.6, against GPT-5.5 and DeepSeek V4 Pro. The side-by-side comparison shows benchmark scores, pricing per million tokens, and provider latency, allowing the team to pick the model that balances cost and performance for their specific codebase.
Evaluating Providers for Cost Optimization
A startup with high inference volume needs to cut costs without sacrificing quality. They check the Pulse feed for the latest price cuts and frontier output pricing. They see Hunyuan HY3 Preview via Tencent Cloud at $0.260 per million output tokens, compare it against other frontier models, and verify the price change is current. They then switch their production pipeline to the cheaper provider, saving thousands monthly.
Researching Models for a New Agent Pipeline
A machine learning engineer is building a multi-step agent pipeline that requires reliable tool use and self-correction. They browse the Agents board and see Claude Sonnet 4.6 rated Excellent with a tau-bench score of 87.5. They compare it against GLM-5 and GPT-5.4, reviewing long-context performance and price per call. The comparison data confirms Sonnet 4.6 stays on-task across long tool loops, making it the right choice for production.
Benchmarking a Custom Model Against the Field
A research lab releases a new open-weight model and wants to see how it stacks up. They search the model directory, find their model, and compare its benchmark scores against DeepSeek V4 Flash and Gemini 3 Pro. The platform shows 58 benchmark refreshes this week, including GPQA Diamond and SWE-bench scores. The lab uses this data to refine their training and position their model competitively.
Frequently Asked Questions
How often is LLM Reference updated?
The data is refreshed every week. Each week, the team tracks new model releases, verifies price changes from providers, and updates benchmark scores across major suites. The Pulse feed shows exactly what changed, including the number of new models, price cuts, and benchmark refreshes from the current week.
What does the Pulse feed show me?
Pulse is a weekly changelog for the entire model market. It reports the number of new models added, verified price reductions from providers, and benchmark score refreshes. It also displays the current frontier output pricing, which is the cheapest price per million output tokens among top-tier models. This lets you see market trends at a glance.
Can I compare more than two models at once?
The primary comparison tool is designed for side-by-side analysis of two models. This focused view lets you see detailed benchmark scores, pricing, and provider information without clutter. If you need to evaluate multiple models, you can use the search and filtering features to narrow down your options before running a direct comparison.
How are the editors picks determined?
Editors picks are based on the latest benchmark scores, real-world performance data, and provider reliability. Each pick is researched and verified against the most current data. For example, Claude Opus 4.7 is picked for coding because it leads SWE-bench Verified and SWE-bench Pro, while Claude Sonnet 4.6 is picked for agents because it has the best generally-available tau-bench score. Picks are updated as new models and benchmarks are released.
Top Alternatives to LLM Reference
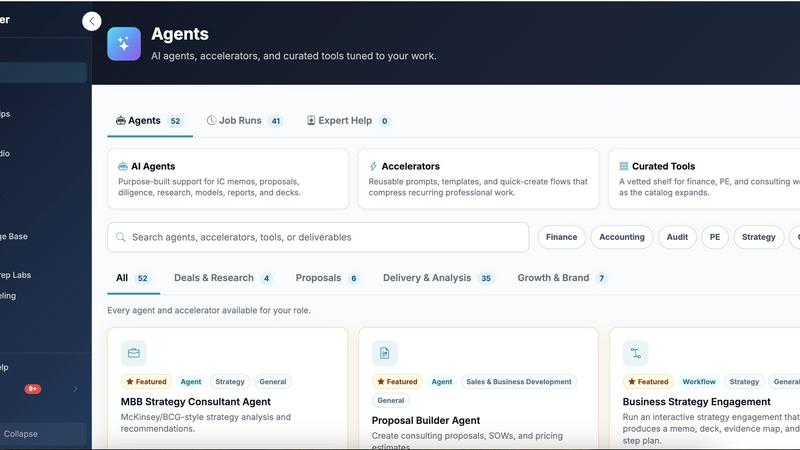
Decker
Decker is the deliverable OS that turns AI drafts into review-ready work and lets you monetize your expertise.
Receptri
Receptri is an AI receptionist that answers calls and chats 24/7 with a human-like voice, learning your business to capture leads and handle urgent.
EchoCall
EchoCall offers 24/7 AI-driven voice and chat support to automate customer service, lead qualification, and appointment scheduling seamlessly.
Pixparkle
Pixparkle is a chat-based AI image and video generator that creates stunning visuals effortlessly with no design skills required.
Cognlay
Cognlay is an AI outbound engine that rewrites follow-ups autonomously by learning from prospect engagement signals.
Overchat AI
Overchat AI crushes standalone tools by giving you unlimited access to the latest models for chat, images, and video in one powerful platform.
Atomic Chat
Atomic Chat is your free, private, local AI with no rate limits, no cloud, and 1000+ models.