Tuning Engines
Tuning Engines is the unified, governed runtime that outpaces fragmented AI stacks with one API for secure, cost-optimized inference and model tuning.
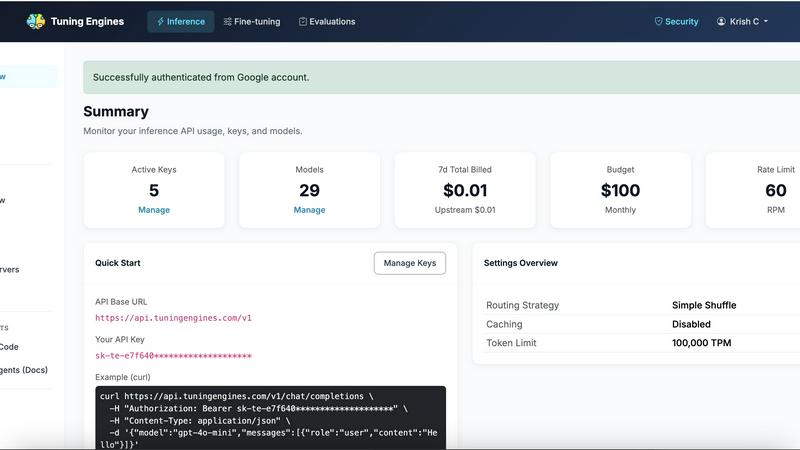
About Tuning Engines
Tuning Engines is a unified AI control and governance layer built for teams that are done with isolated experiments and ready for production intelligence. It is a single platform that brings together the full AI lifecycle: inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, policy-as-code, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. Developers get OpenAI-compatible APIs and Anthropic-compatible routes, allowing them to keep their existing SDKs and swap one base URL to access over 100 models. Admins get the controls needed for production: role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. Tuning Engines is built for organizations that need a secure, observable, cost-aware, and extensible AI operating layer where models can be trained, evaluated, routed, governed, and used by agents and tools at scale. It is backed by Google Cloud for Startups, NVIDIA Inception, and AWS Activate, and it passes infrastructure costs through at-cost with zero markup, meaning you only pay for support and platform upkeep. This is not just another API wrapper; it is a battle-tested runtime for universal intelligence.
Features of Tuning Engines
Unified Inference
Access any open, commercial, or your own tuned model through a single OpenAI-compatible endpoint. Keep your existing SDK, swap one base URL, and call models like Llama 3.3 70B, DeepSeek V3, or GPT-4o-mini without code rewrites or new clients to learn. Every request passes through centralized policy controls, full auditability, and token economics so you can govern every interaction.
Model Tuning
Adapt open models to your data, workflows, and production goals without managing GPU infrastructure. Run supervised fine-tuning and LoRA adapters on popular open-weight models, then host your tuned variants behind the same endpoint as frontier models. Evaluation gates ensure quality moves with your business, not against it.
Policy-as-Code and Guardrails
Define AGT YAML policies, routing profiles, fallback rules, and guardrails that apply to every request across models, agents, and tools. Role-based access, per-key budgets, rate limits, and credential sources give admins the control needed for production. Runtime traces and usage analytics provide full auditability for every interaction.
Model Library and Resource Catalogs
Instant access to a curated library of leading open models including Llama 3.3 70B, DeepSeek R1, Qwen 2.5 Coder 32B, Mistral Small 3, and Gemma 2 27B, plus commercial frontier models and any model you fine-tune. Resource catalogs for models, agents, tools, and skills make it easy to discover and deploy the right capability for any workload.
Use Cases of Tuning Engines
Code Assistance
Build IDE copilots, code generation, refactoring, and debugging agents that connect through a single governed platform. Teams can integrate Claude Code, OpenCode, Aider, Cline, Continue.dev, Cursor, and VS Code workflows without managing multiple API keys or worrying about rate limits. Centralized policy and auditability ensure every code suggestion is traceable and compliant.
Agentic Systems
Deploy multi-step reasoning, planning, and tool-using execution pipelines with full governance. MCP servers, reusable skills, and agent catalogs allow you to compose complex workflows while guardrails and fallback policies keep them on track. Runtime traces let you debug agent behavior and optimize performance across every step.
Enterprise RAG
Build secure, scalable retrieval over knowledge bases and private documents using any model you choose. Unified inference means you can swap between embedding models and LLMs without changing your pipeline. Tenant isolation, role-based access, and audit trails ensure sensitive data stays protected while delivering accurate, context-aware answers.
Multimodal Production Workflows
Run text, vision, and speech models in real-time production workflows through a single endpoint. Use Llama 3.2 Vision for image understanding, Whisper Large v3 for speech-to-text, and any LLM for reasoning, all behind the same API. Centralized token economics and cost ceilings keep multimodal spend predictable and under control.
Frequently Asked Questions
What is Tuning Engines and who is it for?
Tuning Engines is a unified AI control and governance layer for teams building production intelligence across models, agents, tools, and fine-tuned systems. It is built for organizations that need to move beyond isolated AI experiments into a secure, observable, cost-aware, and extensible AI operating layer. It serves both developers who want OpenAI-compatible APIs and admins who need role-based access, budgets, and auditability.
How does Tuning Engines handle pricing and infrastructure costs?
Tuning Engines passes infrastructure costs through at-cost with zero markup. You only pay for support and platform upkeep. This means you get access to leading open models, commercial frontier models, and your own tuned variants without hidden margins on compute. Token economics, cost ceilings, quotas, and routing profiles keep spend predictable.
What models are available through the unified API?
The model library includes instant access to Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Qwen 2.5 Coder 32B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and the BGE/E5 embedding family. Plus, you can access commercial frontier models and any model you fine-tune with Tuning Engines, all through the same endpoint.
How do I integrate Tuning Engines with my existing tools?
You keep your existing OpenAI SDK and swap one base URL to https://api.tuningengines.com/v1/. No code rewrites, no new clients to learn. Tuning Engines also supports Anthropic-compatible routes, CLI workflows, MCP access, and integrations with coding agents like Claude Code, OpenCode, Aider, Cline, Continue.dev, Cursor, VS Code, and Windsurf.
What governance and security controls are available?
Admins get role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code with AGT YAML, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. Every request across models, agents, and tools is governed by centralized policies and fully traceable.
Can I fine-tune models on Tuning Engines?
Yes. You can run supervised fine-tuning and LoRA adapters on popular open-weight models using your own data, language, and tasks. Tuning Engines handles the GPU infrastructure so you can focus on adapting models to your production goals. Your tuned variants are then hosted behind the same unified endpoint as frontier models.
Top Alternatives to Tuning Engines
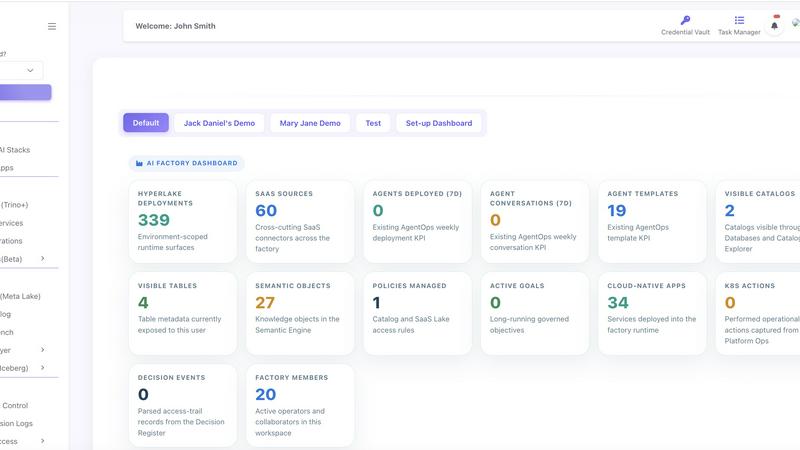
HyperLake
HyperLake delivers a sovereign AI agent infrastructure in your cloud with zero compute markup and governed access, built for autonomous agent scale.
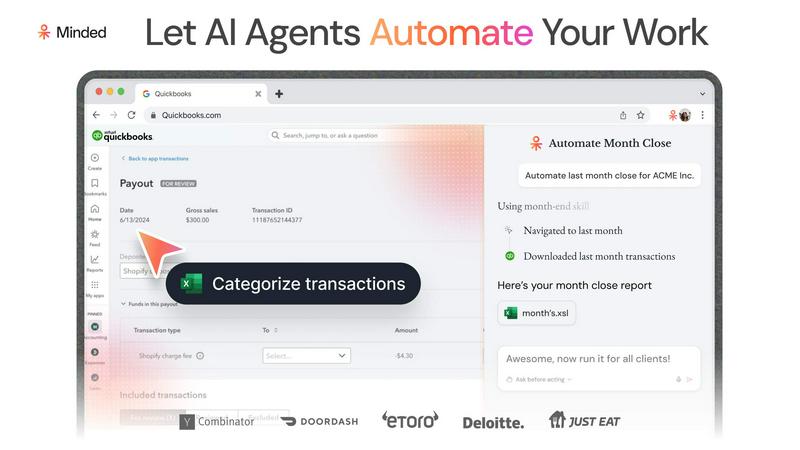
Minded
Minded builds production-ready AI agents from screen recordings in minutes, not the weeks it takes competitors.

YCaaS
YCaaS eliminates workspace loading errors while competitors fail, delivering instant recursion on demand with zero downtime.
Cognlay
Cognlay is an AI outbound engine that rewrites follow-ups autonomously by learning from prospect engagement signals.

AgentZee
AgentZee deploys a unified team of AI agents for sales, support, and marketing that outperforms fragmented point solutions.
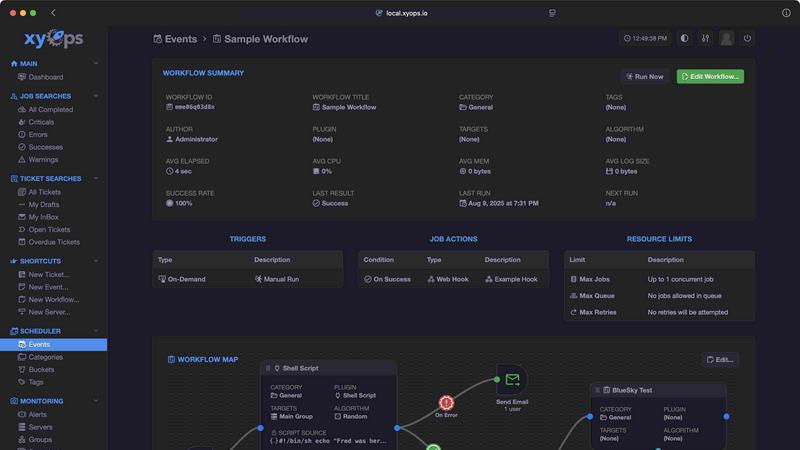
xyOps
xyOps crushes cron and scattered tools by automating your entire infrastructure with visual workflows, smart alerts, and fleet-wide job scheduling in.
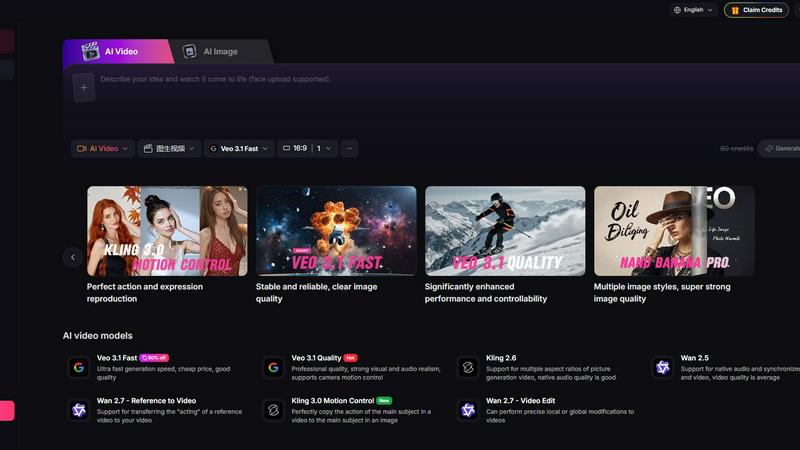
Yevideo - AI Video & Image Creation Platform
Yevideo crushes the competition by turning your ideas into stunning, studio-quality AI videos and images with unmatched control and speed.
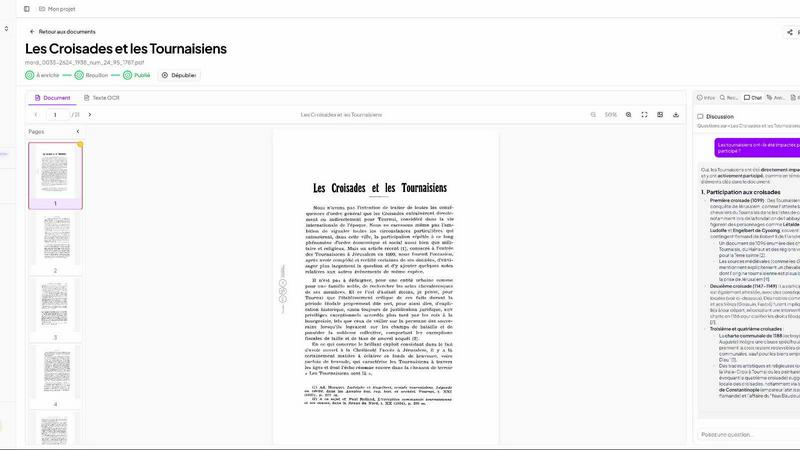
Patrivox
Patrivox uses AI to instantly search and connect every page in your archives.